

MongoDB : Games Data
Task 1: MongoDB : Game Data

1. Create a database named <> and a collection named <> and insert the above data.
2. What is Map-Reduce? Explain the working of map-reduce with an example
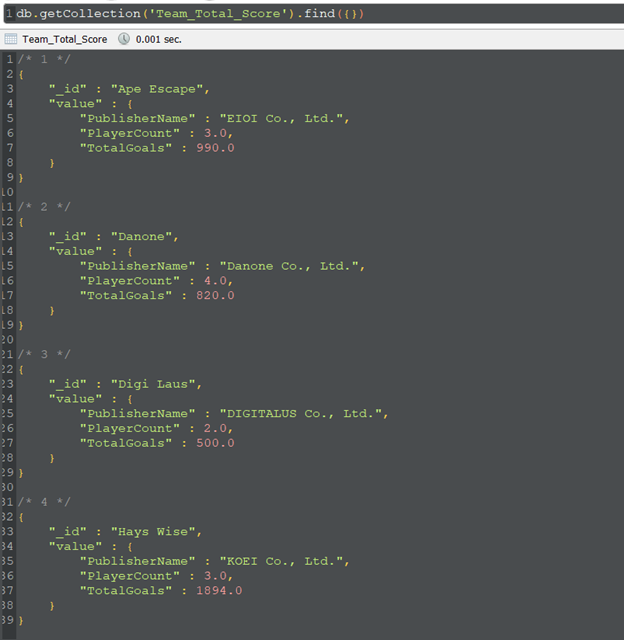
3. Write a reduce function that calculates the total score for each player with the publisher name and count the number of players in each team.
4. Count the number of players in Hays Wise.
5. Remove the player “Alpha” from Ape Escape.
6. Update player name “Jordan” to “Michael” and score to 300.
7. Show all the number of players with their publisher name.
8. Show total goals scored by each country name.
Task 2: Development of a graph database for a given dataset
Find “Task_2_PremierLeauge_2019.csv” file from the Moodle. The dataset contains
information about the English Premier League (EPL) matches. You are expected to
design and create a graph database to visualize the dataset and to answer the following
queries:
- Create a Data Model diagram for “Task_2_PremierLeauge_2019.csv” dataset.
- Create nodes and relationship according to the Data Model which you have created
in question no 1. - Show all the EPL team involved in the season.
- Count all the matches refereed by each referee.
- Who refereed the most matches?
- How many matches “Arsenal” won as the away team?
- Display all the matches that “Man United” lost.
- Display all matches that “Liverpool” won but were down in the first half.
Note:
Find “Task 2 – Match Keywords.txt” file for the keywords used in the EPL matches.
Task 3:
“Column-oriented storage in a database system are more suitable for analytical
reporting than the row-oriented database.” Justify this statement with suitable
example.
=>
Task 1
Question 1





Question 2
MapReduce is a programming framework that allows data to be distributed and processed parallelly on a large sets of data environment. MapReduce consists of two primary tasks, Map and Reduce.
But the overall process of MapReduce can be divided into 6 stages; Input, Input Splits, Mapping, Shuffling, Reducer and Final Output.

To further evaluate the stages of MapReduce with an example, the fig (6)’s breakdown as following:
Input: The initial stage of MapReduce is to gather inputs and store it into blocks of data as provided in one big cluster.
Input Splits: This stage splits every blocks of data and prepare for mapping.
Mapping: Mapping breaks down every unique set of data, in this case every unique set of words and group them together within the block.
Shuffling: Shuffling is responsible to group the similar data from all the other cluster of data and group them together.
Reducer: Reducer reduces the block sizes as unique data of the blocks is divided into key and value pair, key being the actual data and value being the frequency of similar data.
Final Output: Finally, the reduced blocks are clustered into one with each unique data with their frequency as final output of data.
Question 3






Task 2
Question 1














Task 3
“Column-oriented storage in a database system are more suitable for analytical reporting than the row-oriented database.”
Column oriented database stores data by systematically arranging data by column of field, maintaining all of the data integrated with a field adjacent to each other in memory of database. This arrangement of tables is an important factor in analytic query performance because of the drastic reduction of overall disk input and output requirements and ultimately reduces the amount of data needed to load from disk (What Is A Columnar Database? – AWS 2020).
For example, on how a normal table is stored in column-oriented database. Let’s take the following table as a sample.
| Item | Price | Weight |
| iPhone | 999 | 1 |
| Samsung S9 | 899 | 1.2 |
| Google Pixel 3 | 799 | 1.5 |
Each column is divided into separate storage disk, in first storage only the values of “Item” is stored.
| Storage 1 | ||
| Item | ||
| iPhone | Samsung S9 | Google Pixel 3 |
On second storage only the values of price are stored.
| Storage 2 | ||
| Price | ||
| 999 | 899 | 799 |
On third storage only the values of weight are stored.
| Storage 3 | ||
| Weight | ||
| 1 | 1.2 | 1.5 |
The difference in this storage pattern is what makes retrieval of column field for data analysis quick and effective. If analysis had to make for getting the sum of prices of items, the columnar database goes to the storage 2 where all prices are stored and retrieves the values out of it. This saves much processing time and memory because it does not have to go through all rows to get those values of prices.
Advantages of Column Oriented Databases
- Fast at retrieving and comparing data of column values.
- Quick aggregation on larger datasets.
- Compresses data column wise reducing memory usage.
Disadvantages of Column Oriented Databases
- Lacks efficiency for online transaction processing usage.
- Can be comparatively show when queries involve only a few rows.
References
Kiran, R., 2020. Mapreduce Tutorial | Mapreduce Example In Apache Hadoop | Edureka. [online] Edureka. Available at: <https://www.edureka.co/blog/mapreduce-tutorial/> [Accessed 19 August 2020].What Is A Columnar Database? – AWS (2020) available from <https://aws.amazon.com/nosql/columnar/> [19 August 2020]